Quanto è intelligente l’intelligenza artificiale?

Prima di chiederci quali rischi porti con sé l’apparentemente inarrestabile diffusione dell’intelligenza artificiale, forse potremmo domandarci se e quanto l’intelligenza artificiale sia intelligente per davvero.
Il fatto è che, a proposito di intelligenza, non esistono risposte semplici. Sappiamo che, per noi esseri umani, intelligenza è la facoltà di intendere (i latini dicevano, appunto, intelligere) ciò che ci circonda e di estrarne un senso. E poi la capacità di elaborare il pensiero astratto e di imparare, di ricordare, di applicare ad altri ambiti ciò che impariamo e ricordiamo. E ancora: intelligenza è ciò che ci permette di valutare ed esprimere giudizi, di risolvere problemi, di inventare, di entrare in relazione coi nostri simili. Ed è molto altro ancora. Sappiamo inoltre che i ricercatori hanno proposto diversi modelli d’intelligenza, nessuno dei quali tanto soddisfacente da guadagnarsi il consenso dell’intera comunità scientifica.
Sappiamo, infine, che i test del quoziente d’intelligenza sono tutt’altro che affidabili: misurano solo certe prestazioni, facili da valutare dal punto di vista quantitativo. E privilegiano chi appartiene al contesto culturale bianco occidentale, a partire dal quale i test medesimi sono stati costruiti, mentre sottostimano capacità intellettive valorizzate da altre culture.
In sostanza: “intelligenza artificiale” è un nome molto suggestivo e alimenta la nostra meraviglia. Ma sarebbe meglio non prendere l’”intelligenza” delle macchine troppo alla lettera, nel momento in cui non riusciamo a definire bene, in tutta la sua complessità, nemmeno l’intelligenza umana, con la quale dovremmo avere una certa dimestichezza.
Un breve arco di tempo
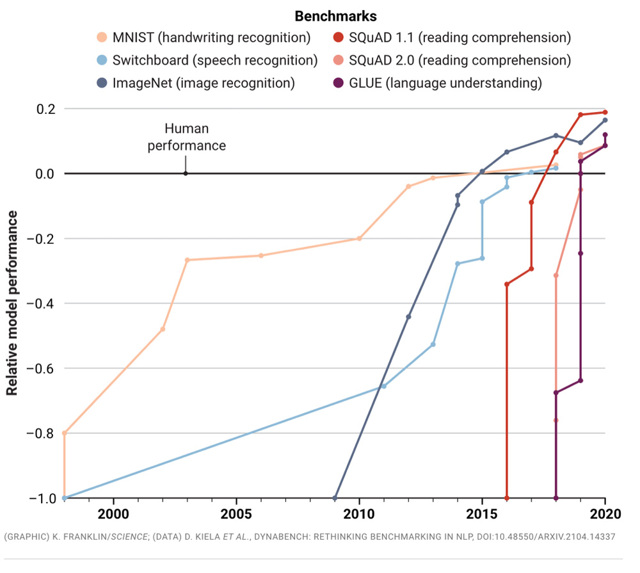
Però niente ci vieta di fare qualche confronto parziale. Potremmo così scoprire – a dircelo è un bell’articolo uscito su Science – un fatto notevole: in singoli compiti che non esiteremmo a definire intelligenti – per esempio, l’elaborazione del linguaggio naturale (Nlp, Natural language processing) – programmi di intelligenza artificiale (Ia) che inizialmente hanno prestazioni di gran lunga inferiori a quelle degli esseri umani possono arrivare a surclassarli nell’arco di un solo anno.
In altre parole: oggi un’Ia può superare meglio di noi un test di comprensione linguistica costituito da domande sull’articolo che stiamo leggendo, anche perché se lo ricorda parola per parola. E la stessa cosa succede con il riconoscimento e la classificazione delle immagini.
Il grafico che segue mostra – ed è piuttosto impressionante – il tempo che ci hanno messo, dal momento del lancio, i diversi programmi di intelligenza artificiale per raggiungere e superare le prestazioni medie umane in compiti che riterremmo squisitamente umani.
Il fatto notevole è che in passato l’Ia è migliorata nell’arco di decenni. Ora, invece, migliora nell’arco di mesi.
Ma non tutto va liscio come sembra.
Quando si esce dal laboratorio, l’intelligentissima intelligenza artificiale compie errori stupidi. Può non capire il senso di una frase che finisce con una negazione: per esempio “pensavo che il volo sarebbe stato terribile, ma non lo è stato”. Oppure può essere incapace di rispondere a domande ambigue, o che hanno più di una risposta corretta. Può fare pasticci con i numeri. Può soffrire di allucinazioni, anche perché il suo enorme archivio-dati non distingue tra testi fattuali e testi di narrativa fantastica.
O, ancora, può replicare e amplificare i pregiudizi di chi l’ha programmata. Per esempio, un’Ia addestrata a selezionare personale sulla base di curricula prevalentemente maschili può penalizzare candidature femminili (questo è successo ad Amazon).
Tutto ciò non è per niente intelligente.
Oppure, un’Ia calibrata per valutare perfettamente immagini mediche provenienti da un laboratorio può trovarsi del tutto spaesata di fronte a quelle che le arrivano da un laboratorio diverso, e un’Ia capace di intercettare gli insulti razzisti può non intercettare quelli sessisti.
Un lavoro infernale
Tutto ciò ci dice un paio di cose: l’intelligenza artificiale è molto veloce, molto potente e molto specializzata. Non ha, almeno per ora, la flessibilità propria dell’intelligenza umana, che integra esperienza sensoriale, competenze pragmatiche ed emotive e pensiero astratto. A un bambino basta vedere una decina di gatti per capire che cos’è un gatto: può girarci attorno, accarezzarlo, prenderlo in braccio e dargli da mangiare. Sarà anche capace di riconoscere un gatto di ceramica alto cinque centimetri, o un gatto in un cartone animato, o un costume carnevalesco da gatto, e potrà disegnarlo o descriverlo, il gatto.
All’Ia, che non ha un corpo, non si traveste per carnevale e non accarezza i gatti, servono migliaia e migliaia di esempi selezionati ed etichettati come “gatto” per imparare a riconoscerne uno (di etichettatura dei dati abbiamo già parlato nel primo articolo di questa serie).
Quando infine diventa capace di farlo, e lo fa in modo velocissimo, può tuttavia sfuggirle il senso dello Stregatto di Alice, o può spaesarsi se trova la didascalia “Il gufo e la gattina” sotto le foto di Barbra Streisand e George Segal.
Un recentissimo articolo uscito su Britannica è molto tassativo su questo tema: “I ricercatori non sono in grado di modellare neanche il sistema nervoso di uno scarafaggio”, e figuriamoci quello di un essere umano. Dunque, è difficile pensare che comportamenti altamente complessi come la comprensione, la pianificazione e il ragionamento possano emergere dalla semplice integrazione di capacità di base, per quanto potenziate e velocizzate. Non vuol dire che non ci arriveremo, ma di certo non ci siamo ancora.
Tra l’altro: selezionare ed etichettare dati per l’intelligenza artificiale è un lavoraccio che chiede un sacco di manovalanza. E può trattarsi di manovalanza sottopagata ed esposta a condizioni, letteralmente, infernali.
Ce lo racconta un’inchiesta di Time: Gpt3, la penultima versione di ChatGpt, addestrata su miliardi di testi tratti da internet, ha impressionanti capacità linguistiche, unite però a un’imbarazzante propensione a riproporre i commenti sessisti, violenti e razzisti di cui internet trabocca.
Nell’impossibilità di eliminare manualmente tutti gli input tossici riesaminando a uno a uno i dati già caricati, la OpenAi, l’azienda a cui ChatGpt fa capo, pensa di costruire un programma addestrato apposta per rilevare il linguaggio tossico. E, poiché l’unico modo per spiegare all’Ia come riconoscere il linguaggio tossico è fornirle un’enormità di esempi già etichettati come “tossici”, delega questo compito a Sama. Si tratta di “un’azienda con sede a San Francisco che impiega lavoratori in Kenya, Uganda e India per etichettare i dati per clienti della Silicon valley come Google, la Meta e la Microsoft. Sama si presenta come un’azienda di ‘intelligenza artificiale etica’ e afferma di aver contribuito a far uscire dalla povertà più di cinquantamila persone”.
L’inchiesta di Time racconta però come in Kenya siano stati impiegati lavoratori pagati un massimo di due dollari l’ora, su turni di nove ore, per etichettare testi di contenuto violento, sessista o pornografico. Tutti hanno subìto pesanti conseguenze a livello psicologico.
Se qualcuno ha avuto la fantasia di un’Ia sempre al servizio degli esseri umani, be’, sembra che succeda anche il contrario. E, per gli esseri umani, mettersi al servizio dell’Ia può essere faticoso, malpagato e traumatico.
Sintesi meccanica
Restiamo dalle parti di ChatGpt e del suo essere, o meno, “intelligente”.
È il New Yorker a sostenere che ChatGpt non è altro che una copia sfuocata del web. L’argomentazione è convincente: per funzionare, ChatGpt individua ed estrae le regolarità statistiche, cioè le formule linguistiche più ricorrenti, dalla sterminata quantità di testi che prende in rete. Lo fa a partire da un modello che mette in fila le parole selezionandole in base alla probabilità che ciascuna parola segua la porzione di testo che la precede.
In questo modo può restituire, rispondendo a qualsiasi richiesta (prompt) e in una forma grammaticalmente corretta, non una specifica informazione, ma qualcosa che è la sintesi meccanica di quanto appare con maggior frequenza in migliaia di contenuti che condividono una o più parole o sequenze di parole-chiave. Il risultato è un discorso formalmente impeccabile, a cui manca però ogni profondità e, per così dire, ogni spigolo.
“Qualsiasi analisi di testi tratti dal web”, spiega il New Yorker, “rivela che frasi come ‘l’offerta è bassa’ spesso appaiono vicino a frasi come ‘i prezzi salgono’. Un chatbot che incorpora questa correlazione può, quando viene posta una domanda sull’effetto della carenza di offerta, rispondere parlando di aumento dei prezzi”. Ma se un grosso chatbot com’è ChatGpt incorpora così tante correlazioni tra termini economici da poter offrire risposte plausibili e ben formulate a molte domande sul tema, questo non vuole dire che capisca la teoria economica.
D’altra parte, ogni giorno viene prodotta un’enorme quantità di testi di servizio, ai quali non si chiede né profondità né originalità. Quindi possiamo usare l’Ia per riconfezionare in un battibaleno materiali tratti dal web risparmiandoci la fatica della ricerca e sicuramente eludendo il copyright (su questo tema torniamo in seguito). Otterremo però contenuti via via più generici e sfuocati, specie quando la macchina comincerà a riconfezionare materiali che essa stessa ha confezionato, amplificando le sfuocature e moltiplicando fraintendimenti, errori e allucinazioni come questa, riguardante la “stretta relazione” che avrebbe unito il filosofo Platone e l’attore Laurence Olivier.
Intanto – e anche questo va detto – in tutto il mondo una sterminata schiera di persone continua a interrogare l’Ia ponendole domande insidiose, con l’esplicito scopo di svelarne le debolezze.
E, con ciò, ponendo anche l’intelligenza collettiva al servizio dei ricercatori che lavorano per scovare i difetti e migliorare le prestazioni dell’Ia.
In conclusione, il New Yorker ci esorta a non antropomorfizzare la macchina. Questo è del tutto controintuitivo, perché è proprio la caratteristica capacità di riformulare testi esistenti a darci l’illusione che ChatGpt “capisca” qualcosa.
Del resto, la nostra comunicazione umana si fonda sul presupposto che chiunque ci risponda a tono possa e voglia capire quanto gli diciamo. Difficile, dunque, resistere alla tentazione istintiva di estendere la facoltà della comprensione anche all’Ia.
Umorismo e incantesimo
Troviamo però un indizio notevole sulle effettive capacità dell’Ia se consideriamo una delle più squisite e peculiari facoltà umane: il senso dell’umorismo. “L’umorismo”, scrive Jacopo Cirillo sul Tascabile, “è sempre una combinazione di wit e wisdom, spirito e saggezza. La saggezza di conoscere il mondo e lo spirito adatto (l’arguzia, se preferite) per avere a che fare con le persone. Attenzione, però: saggezza non significa nozionismo o semplice conoscenza. La semplice conoscenza – quella insegnabile a un bot in maniera intuitiva e semplice – è per esempio il sapere che il pomodoro è un frutto; la saggezza è quella di non metterlo in un’insalata di frutta”.
Certo, l’Ia, se richiesta, può raccontarci una barzelletta. Anzi: più barzellette di quante un essere umano possa tenere a mente.
Ma per insegnare a una macchina come diventare spiritosa (e renderla, con questo, davvero indistinguibile da noi) dovremmo prima di tutto trasferirle i meccanismi logici (per esempio, il ribaltamento) su cui si fonda la comicità. Questo si può fare: basta darle una sufficiente quantità di dati. Dovremmo poi darle la saggezza necessaria a non mettere pomodori nell’insalata di frutta, e questo è già più complicato. E dovremmo – cosa a oggi impossibile – renderla consapevole di sé, del contesto e del tipo di relazione che c’è con il suo interlocutore.
Racconta Cirillo che, quando lui prova a scherzare con la macchina, quella “si arrabbia”. Rifiuta, cioè, lo scarto logico dell’umorismo, e in automatico rientra nei confortevoli canoni delle risposte previste dalla media statistica: quelle che “sembrano”, ma non sono, frutto di autentica comprensione. L’articolo, tra l’altro, è oltre che illuminante anche molto divertente.
Su un tema per certi versi analogo, lo scrivere poesie, pubblica un articolo altrettanto illuminante e divertente l’Atlantic: ChatGpt è pronta a poetare (e, se serve, lo fa rispettando anche la metrica) su qualsiasi argomento, dalla tassa di successione ai calzini. E così esordisce: “Oh, calzini, fidi compagni dei miei piedi!”. Questa prestazione peraltro conferma la sua assoluta mancanza di senso dell’umorismo.
Ma a mancare è soprattutto l’incantesimo che la poesia sa creare, proprio per la sua natura di “schema linguistico che comprime dati disordinati di esperienza, emozione, verità o conoscenza trasformandoli in discorso memorabile”.
E ancora: la newsletter di Axios racconta invece che religiosi di fedi diverse (pastori luterani, rabbini) provano ad affidarsi a ChatGpt per scrivere sermoni, per esempio compilando un prompt come “Predicami la resurrezione di Lazzaro in Giovanni, 11”.
I riferimenti biblici e teologici e le conseguenti esortazioni prodotte dall’Ia risultano pertinenti, ma il discorso nel suo complesso vien fuori noiosetto e privo di empatia e compassione.
Insomma, è senz’anima.
C’è però un curioso utilizzo di ChatGpt che sembra delineare una certa capacità inventiva. A raccontarcelo è il Guardian: Alexandra Woolner, che pubblica i suoi lavori all’uncinetto su TikTok, prova a domandare all’Ia di scrivere uno schema per produrre un narvalo all’uncinetto. Dopotutto, l’Ia sa scrivere stringhe di codice, e dopotutto anche le istruzioni per lavorare all’uncinetto vengono espresse in un astruso codice fatto di asterischi, parentesi e abbreviazioni.
ChatGpt produce uno schema plausibile. La signora esegue. Il video che mostra il risultato sfiora il milione di visualizzazioni. Il prodotto è quello che vedete qui sotto. È minuscolo, ha due pinne e somiglia a una creatura marina, “carina ma inquietante”. La signora decide di chiamarla Gerald.
Ora, proviamo a seguire Gerald che, con la mediazione di un’artefice umana, viene concepito come stringa di codice e poi diventa qualcosa che possiamo vedere, e che potremmo toccare. Cominciamo così ad addentrarci nell’universo delle immagini: quelle che ci restituiscono l’aspetto di entità fisiche, e quelle che traducono in forma visiva idee e fantasie.
Se da un chatbot come ChatGpt passiamo a un’intelligenza artificiale Tti, cioè Text to image (dal testo all’immagine), le cose cambiano e diventano un po’ più complicate. Stiamo parlando di macchine che non scrivono, ma producono immagini a partire da istruzioni espresse in parole. Si chiamano Dall-e 2, Midjourney, Stable Diffusion.
Anche queste Ia lavorano a partire da dati etichettati, cioè da un’infinità di immagini corredate da descrizioni. Ma non si accontentano di catalogarle, come fa per esempio l’Ia che elabora radiografie, o quella per il riconoscimento facciale. Possono eseguirne di nuove mimando una miriade di tecniche diverse, dalla pittura a olio all’illustrazione al tratto, alla fotografia. Possono clonare lo stile di un singolo autore del quale dispongano di una sufficiente serie di esempi. Possono interpolare gli stili di più artisti.
L’interazione tra l’Ia e l’essere umano che le propone un prompt prevede dunque non un singolo livello di interazione, ma almeno tre livelli: quello del soggetto dell’immagine, quello della tecnica, quello dello stile. Modificando l’input a ciascuno di questi tre livelli, il risultato cambia.
C’è anche uno scarto in più, nel passaggio da un prompt verbale a una risposta visiva, perché è difficile che un comando verbale possa descrivere un’immagine in ogni suo dettaglio, sfumatura, scelta compositiva. Gli ambiti, diciamo così, di libertà interpretativa della macchina sembrerebbero molto più ampi. E infatti.
Nel momento in cui una macchina governa ambiti così ampi di espressione, quanto ci risulta difficile ricordarci che è “una macchina”?
E infatti, mentre a proposito dell’Ia che parla e scrive il dibattito pubblico si è subito spostato sulla sfocatura dei contenuti, l’apparente precisione formale delle risposte, la loro sostanziale carenza di componenti emotive e gli “errori stupidi”, invece il dibattito sull’Ia che restituisce immagini ha preso immediatamente altre strade: si può o meno fare arte con l’Ia? Possiamo ancora definire “autore” di un’immagine qualcuno che, nella realtà, ha scritto un testo, l’ha corredato di indicazioni su tecnica e stile, e infine ha scelto la più soddisfacente tra le innumerevoli interpretazioni alternative fornite dalla macchina?
E, ancora: nel momento in cui una macchina governa ambiti così ampi di espressione, quanto ci risulta difficile ricordarci che è “una macchina”? “La mia impressione”, scrive Gregorio Mancini su Singola, “è che con i Tti, già al livello attuale, ci stiamo affacciando nella zona grigia tra strumento e persona: tra la generica autonomia che hanno tutti gli oggetti e l’autonomia non circoscrivibile che fino a tempi recenti avevamo riscontrato solo tra esseri viventi. Nell’arte, questi strumenti persona che sono le Ia devono essere intesi come una metà di un essere duale che diventa realmente creativo solo quando la parte umana e quella artificiale si fondono”.
Il punto di vista può non essere condivisibile, ma è di sicuro suggestivo.
Addestrare la macchina
Giusto per ricordarci nuovamente che di macchine stiamo parlando, forse vale la pena di compiere una piccola digressione sui modi in cui può essere addestrata un’Ia di tipo Tti. Provo a raccontarne qualcosa.
Ormai sappiamo che bisogna in primo luogo caricare una quantità di dati, cioè di immagini corredate da descrizioni testuali, in modo che l’Ia possa correlare le une con le altre.
Poi le tecnologie divergono in base all’obiettivo che si vuole perseguire: produrre immagini fotorealistiche, oppure ottenerne di inedite. In questo secondo caso anche tecniche e stili vanno etichettati e correlati.
Un modello di apprendimento può essere basato sul Generative adversarial network (Gan). In sostanza, ogni descrizione è tradotta in numeri che ne indicano il contenuto semantico. A partire da questi, una rete neurale generativa produce una nuova immagine.
Le immagini prodotte nelle fasi iniziali possono essere “rumorose” (cioè sporche, imprecise). La cosa interessante è che la rete neurale che produce immagini (il generatore) viene messa in competizione con una seconda rete neurale antagonista (il discriminatore), il cui compito è distinguere tra immagini generate ex novo e immagini originali.
In questo modo, e grazie alla retroazione, ciascuna delle reti neurali migliora le prestazioni dell’altra. L’Ia è ottimizzata quando le immagini generate sono così realistiche da risultare, per il discriminatore, indistinguibili dagli originali.
Il Variational autoencoder (Vae) è invece il modello più usato per produrre illustrazioni. E anche in questo caso il processo è in sé interessante.
I dati inseriti vengono compressi da un encoder in una rappresentazione latente (una sequenza di valori numerici che rappresentano linee, forme, colori…) e quest’opera di riduzione permette di estrarre le informazioni più rilevanti scartando le variazioni non significative. Sarà un decoder, attraverso un processo di campionamento casuale, a costruire un’immagine inedita, che viene poi regolarizzata per ridurne le imprecisioni e che idealmente non è uguale a nessuna delle immagini caricate, anche se da queste trae tutte le caratteristiche salienti.
Un terzo modello (Diffusion) lavora direttamente sull’immagine, che viene generata a partire da rumore casuale (immaginiamo uno schermo pieno di pixel). Durante una sequenza di passaggi, l’Ia fa in modo che il rumore si addensi, costruendo tratti via via più dettagliati, nei punti in cui, a partire dal suo addestramento, ritiene che quell’addensamento debba essere più probabile.
In realtà, pensare che qualsiasi immagine, dal Giudizio universale di Michelangelo a Topolino, al ritratto di Gandhi, possa essere triturata e scomposta in infinitesimi brandelli di informazione, o in puro rumore, e poi ricomposta in forma diversa, è abbastanza sconcertante.
Forse smette di esserlo se pensiamo che, dopotutto, quanto avviene con le Ia Tti non è più complicato o sorprendente di quanto avviene tra la nostra retina e il nostro cervello. A parte il fatto che le immagini noi ce le selezioniamo e ce le etichettiamo da sempre e ce le ricostruiamo nella mente da sempre.
O, forse, tutto ciò può apparirci ancora più sconcertante.
Un’altra cosa che il nostro cervello sa fare molto bene è combinare elementi esistenti in modo inedito e appropriato (cioè: non casuale, arbitrario o inutile). In questo atto c’è l’essenza della creatività che, poiché niente si crea dal niente, è intrinsecamente, come scrive Umberto Eco, ars combinatoria.
Ecco: un altro fatto notevole è che, sul combinare, anche l’Ia va alla grande.
La cosa più sorprendente, scrive la Mit Technology Review del Massachusetts institute of technology, è che l’Ia “può prendere due concetti non correlati e metterli insieme in modo per molti aspetti funzionale”. Qui sotto, la combinazione tra una poltrona e un avocado, realizzata con Dall-e 2.
Qui, invece, alcune immagini ottenute utilizzando il medesimo prompt con Midjourney. E, bisogna dirlo, un paio di queste poltroncine sono dotate, oltre che di intrinseca congruenza con la richiesta espressa dal prompt, anche di una discreta valenza estetica.
Tutto ciò può dar luogo a un’infinità di domande, alle quali per ora ci sono, mi pare, poche e incerte risposte.
Per esempio: può un’Ia, che non è né senziente né, in senso proprio, intelligente, e che non ha alcuna intenzionalità, produrre risultati dotati di qualche valore creativo?
O può essere invece che lo spazio creativo dell’Ia stia proprio nelle lacune che, dal prompt all’esecuzione di un’immagine, l’Ia deve riempire in modi che sfuggono alla previsione degli agenti umani? E, magari, può essere che la creatività delle macchine stia perfino nelle imprecisioni della programmazione (pensiamo alle “allucinazioni” di ChatGpt).
Soprattutto, ammesso e non concesso che i risultati inediti dell’ars combinatoria di un’Ia abbiano qualche sorta di valore, possiamo davvero parlare di “creatività”?
E ancora: quanta creatività umana viene scippata dall’Ia, che pesca dal web non solo figure ma anche tecniche e stili che sono propri di un singolo artista? E come è possibile proteggere efficacemente con un copyright non un’opera o un complesso di opere, ma lo stile che le accomuna?
“L’inquietante verità sul copyright dell’Ai è che nessuno sa cosa succederà dopo”, scrive The Verge.
Il problema non riguarda solo le immagini, ma anche la musica e la scrittura. “Se dai all’Ia dieci romanzi di Stephen King” (e magari, aggiungo io, un’elementare traccia della trama) “e le dici di produrre un romanzo di Stephen King, si tratta di un uso corretto?”.
E che cosa succede se l’intelligenza artificiale riesce, letteralmente, a leggere quanto accade nel nostro cervello? Un recentissimo articolo uscito su Science ci dice proprio questo: a partire dalle sole scansioni cerebrali, l’Ia può, dopo adeguato addestramento, riconoscere e ricostruire le immagini che una persona sta vedendo.
Per certi versi si tratta, se non di una vera e propria lettura delle mente, almeno della lettura di una specifica e complessa attività cerebrale. Qui il confronto tra le immagini viste dagli occhi umani (sopra) e le immagini autonomamente ricostruite dall’Ia a partire dalle onde cerebrali (sotto).
È ancora più recente (14 marzo 2023) l’annuncio del lancio di Gpt-4, un’evoluzione di Chat-Gpt che accetta input non solo di testo ma anche di immagini, ed “è più affidabile, creativa e capace di gestire istruzioni sfumate o ambivalenti” di quanto non fosse la versione precedente.
Nello stesso giorno, Google ha annunciato la prossima introduzione di funzionalità proprie dell’Ia dentro i servizi di Gmail, Google Docs e altre app proprietarie. Per esempio, dovrebbe essere sufficiente fornire a Gmail una semplice lista a punti perché questa generi un’email completa.
Il terzo (e, per ora, ultimo) articolo di questa serie proverà a raccontare alcune possibili conseguenze di un così tumultuoso, rapido e sorprendente succedersi di cambiamenti.
Questo è il secondo di quattro articoli di Annamaria Testa dedicati all’intelligenza artificiale: